
Hi all,
For a while now, I wanted to write about networking automation. I see a lot of different views on this market and a lot of confusion. As this can really impact your business, you want to make the right decisions and investments going forward.
I have been working in the network automation space for over 17 years and I hope I can share some valuable insights to help you. When I started in this space in 2002, I was part of a team that built the first release of a network provisioning system for the Rabobank group. Since then, I have been involved in evaluating, selecting, implementing and building network automation solutions for many customers. I ended up starting NetYCE together with my business partner Eric Yspeert when we saw a gap in the market.
Let me start by giving you my definition of network automation. I define it as:
“The ability to automate configuration changes and related engineering change processes that allow you to create, update and delete end-to-end networks and services across multi-vendor and multi-domain networks. Ideally, with the flexibility to build any automation use-case, irrespective of the chosen network design.”
How it’s done today
In essence, any network goes through (re)design-, build- and deploy cycles. See picture below.
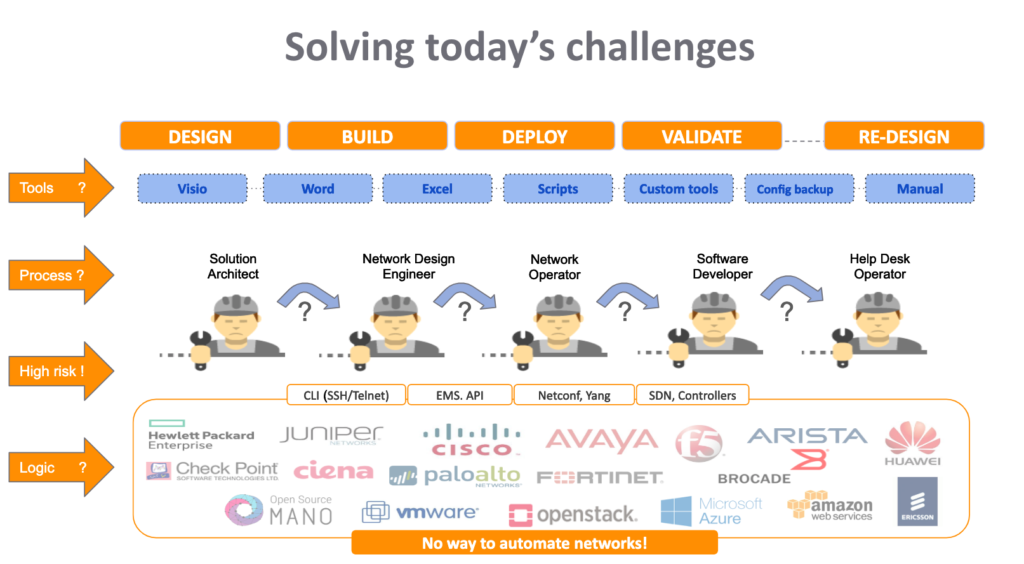
What you see is that network designers, engineers and operators work with Word, Visio, Excel and Notepad to document what they do and they end up building configs and jobs to make the required network changes. In some cases, scripts are used.
Once deployed, there are lots of validation and troubleshooting activities that require logging into the production devices to fix things? and keep on fixing things. This approach is often chaotic and unstructured, to say the least. A well-defined process to manage the design, build and deploy cycles is non-existent and left to the interpretation of individual persons.
So, in the end, network devices get configured as deemed best by the individual, resulting in configuration drift and different logic applied on production devices (both physical and virtual). In all my years in this business, I have seldom seen it being done more efficient. But as network automation becomes more popular, these processes finally need to get optimized.
Desired situation - Control the full life cycle
So when looking at solution requirements for network automation, you need to consider the full life-cycle around designing, building, deploying and validating network & config changes. See picture below.
This is where the confusion really starts, as most people consider network automation to only deal with job automation and config change management (backup and diff configs from production devices) or only focus on a single domain or single use-case solutions.
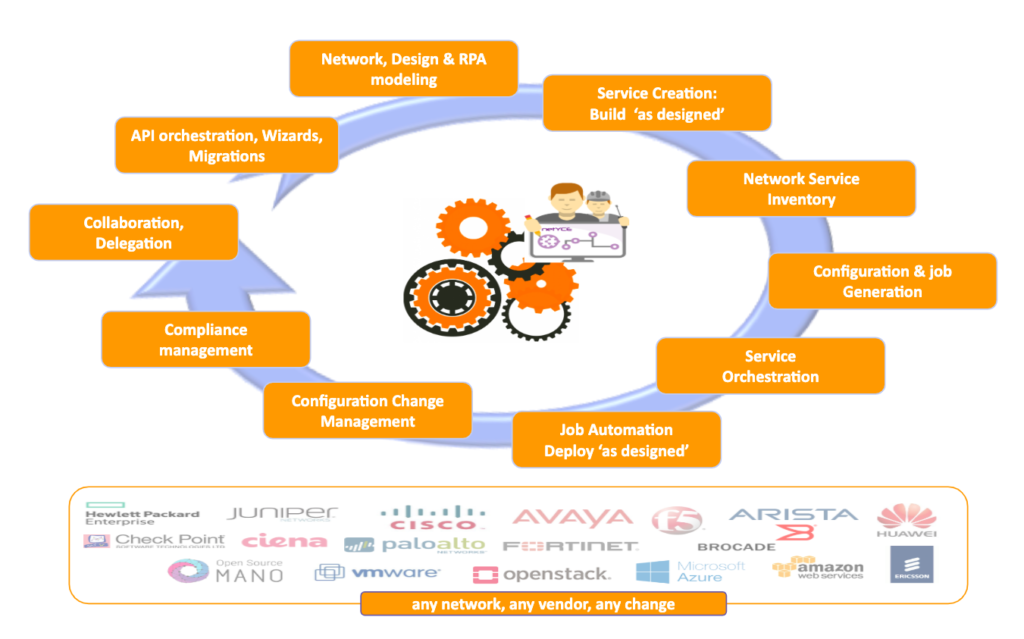
To control the full life cycle, you need to be able to automate all different process steps. Let’s quickly run through them, starting at the top.
- Modelling of network types, designs & processes. Let me keep it simple and describe this as the capacity to digitize (model) your design choices and change processes so you can instantiate these models to auto-create the data and logic for the services you want to deploy.
- The outcome of this instantiation process basically creates the data (objects, relations, parameters and variables) that reflect your desired ‘as-designed' situation with all the nitty-gritty details. You want this stored in a database inventory (to replace Excel) and use it to auto-create full or partial configs and jobs, given your design criteria. For this, you combine the data with a smart templating mechanism.
- To deploy these ‘as-designed’ configs and jobs in your network you want to use checks and validations that you can define yourself. This can be done with run-books (in Ansible) or scenarios (in netYCE). You also want to be able to use this data to orchestrate service changes with other systems like IPAM, DNS, DHCP, cloud domains etc
- Once deployed, you want to keep track of what gets changed outside of your control. This can be done by backing up configs and checking changes that people made in production.
- The next step is that you want to be able to run your compliance rules against the deployed configurations to check your compliance and schedule new jobs into the network to (auto) mitigate the inconsistencies.
- Now, what is overlooked in many cases is the ability to collaborate with other engineers. To be able to plan and prepare your changes before deploying them. This is done by storing your engineering logic in templates and use an integrated database that stores your network inventory details. This can also be used for the migration of use-cases and standardization of your change processes.
- Finally, you want full API support on your system so any change (via your collaboration GUI) can also be done by invoking it from any 3rd party application. Or create your own wizards on top of the API that allows things to be integrated with other processes.
What the market considers network automation
Let me give you a bit of a historical perspective and categorize the different types of solutions that I have encountered so far. My objective is to highlight the different approaches that vendors have taken to solve the challenges around automating network configuration changes. It is by no means complete or a comparison of different solutions, but merely to give you more insight into how they match the requirements I defined above.
Originally the domain of network automation was led by vendors like Opsware (acquired by HP, now HPNA), Intelliden (acquired by IBM), Netmri (acquired by Infoblox) and BladeLogic (acquired by BMC). They called themselves automation tools, but if you looked more closely, the main focus was network configuration management; i.e. doing configuration backup of (multi-vendor) network devices with some basic command-job automation and possibly some compliance checks. Typically these solutions also had some kind of network monitoring functionality to check changes happening in the network.
The second wave of solutions were software vendors that can be best classified as commercial applications offering a predefined way of dealing with certain use-cases and/or type of networks. These can be a good fit for certain use-cases, but as they lack the flexibility to build your own specific use-cases, they can not be classified as (open) frameworks. I would say that vendors like Anuta networks, Solarwinds, Apstra and Glueware fall into this category.
Another category is solutions from network equipment vendors such as Blueplanet (Cienna) and Cisco NSO (former Tail-f). These are a mix of an application with some elements of a framework but typically lack the openness, flexibility and ease of use that engineers demand nowadays. And they can be quite expensive. What characterizes them is a focus on runtime execution with vendor modules and libraries that contain the vendor’s OS syntax options in an effort to abstract the CLI for network engineers.
This can work well for service providers that have fairly standardized designs and services, but once you have specific design choices (as most do) and/or multi-vendor and multi-domain requirements, you end up with customization requiring lots of (new) software development skills. I see customers who buy network equipment from these vendors often start off with these solutions, but as customization is cumbersome and labour intensive, network engineers start looking for other solutions.
In today's world when it comes to network automation, engineers are looking for agile and cheap frameworks that offer the flexibility to build any type of solution and use-case they want for any type of network. So it’s logical that engineers started looking for Open Source solutions. In this category, you see tools that originated from the systems management domain, offering configuration management for (large) server environments, like Ansible, Puppet Chef and Saltstack.
Some of them have evolved quite well over the last few years to also automate configuration changes and jobs on network devices. Especially Ansible is very popular amongst network engineers nowadays with a big user community. Their main challenge, however, is that their key focus lies in device automation, or what I call, runtime automation. So instead of servers, you can now automate configuration changes on (many) network devices. But as these solutions didn’t originate from the network domain, many things you need for network and service provisioning are not readily available, such as managing the data, topology, dependencies, network specific parameters, relationships and design abstractions. I am not saying it can’t be done, but you again need lots of programming skills and time to be able to build what you want. And you end up buying commercial versions like Ansible Tower in order to do this.
Then you have the programming frameworks (languages) that offer full flexibility like Python, Perl and other scripting languages. Especially Python has become very popular with numerous GitHub libraries like Netmiko, Napalm, Jinja2 and others developed by the open source community. Again, and even more so, the main challenge here is that you need to be more of a software developer than a network engineer to achieve what you want. And support is a key concern as whatever gets built will need to be supported by whoever built it. In many cases, when people leave the company, other people stop using it.
Another challenge with this programming approach is that solutions end up developed for a single domain or single use-case situations. So you end up with different solutions, scripts and data sources that don’t work together and are not shared amongst different teams in the company.
Then there is another category altogether with solutions like Onap, OpenMano, OpenStack and others that also originated from the open source domain aimed to offer complete framework solutions for mainly virtual domains. I would categorise them as an ‘IT-approach’ to network automation as they deal with the creation and orchestration of VNFs, storage, supervisors etc. As far as network automation, they primarily deal with the process of spinning-up (or down) VNF’s that have a pre-set of configurations.
Now, of course, it’s now far easier to spin up a VNF (e.g virtual firewall) with a base config than setting up and configuring a hardware box. But in the end, these VNFs still run a specific vendor OS (Cisco IOS/XR, Junos, Checkpoint etc) and they still need specific syntax commands to be configured in a certain way in order to build end-to-end services. And in many cases, you also need to configure the PEs, Access devices and CPEs with attributes like VLANs, IP addresses, NNIs and what have you. Therefore, these solutions don’t fit my definition of network automation solutions.
Finally, there is the category that I call domain-specific solutions offered by networking vendors such as SD-WAN solutions (Versa), SDN controllers (Nokia Nuage) and solutions like Cisco ACI and many others. These also cannot be classified as network automation solutions, as in the end, these are merely innovative network solutions for a specific domain with some additional automation capabilities.
What route to take?
Let’s now look back at my earlier definition of network automation:
“The ability to automate configuration changes and related engineering change processes that allow you to create, update and delete end-to-end networks and services across multi-vendor and multi-domain networks. Ideally, with the flexibility to build any automation use case, irrespective of the chosen network design.”
If I look at solutions that match this definition and actually offer the freedom and flexibility that engineers want, this only leaves development frameworks like Ansible, Python and netYCE in my opinion. There are some differences of course, but they all represent an open framework that enables engineers to develop what they want. Depending on your desired level of programming skills (from high to low), you can choose, for Python, Ansible and netYCE. I may be biased of course, as I also represent netYCE, but many other thought leaders in this industry share this opinion. If you want to judge for yourself, please check out my next blog, where I’ll do a detailed comparison of these three options.
In summary, what Network Automation is and what it isn’t
Let me finish with some key takeaways.
Network automation is not:
- (Only) about automating config changes on devices. As pointed out, this is only a minor aspect of all lifecycle change processes to be taken into account.
- ‘Auto-magic’. There are people who think that network config change can be magically automated. This is not the case. You need to put your network knowledge and thoughts into a system so it does what you want to automate.
- About requiring new network hardware or solutions. As said, these are nice for domain improvements and innovations but lack any of the other automation requirements.
- To be confused with automating processes like fault-, performance-, security or nowadays also AI management. Although these can be tied into network configuration and change automation they represent different aspects of the FCAPS model
- About becoming a software developer. Of course, as a network engineer you need to develop new skills but depending on the solution you choose you can decide how much (or less) of a coding guy you want to become.
- About SDN or NFV. These are merely new technologies that, at best, cover some piece of automation.
- About losing your job as a network engineer. This has been a fear of many engineers in the past, but I can assure you that networking and especially the need for skilled network engineers will stay around as long as we need data services, and especially the need for skilled engineers with automation experience.
What network automation is all about:
- Managing data-data-data! In the end, every configuration is ‘only’ a combination of networking data and syntax. Once you control the data and the syntax of your specific vendors and designs (or things like YAML), you are on the right track.
- The digitisation of processes and designs. The prime goal is to standardize config changes in your network. Once you tie your design models to generate standardized data, you’ll be able to easily drive efficiency and quality throughout your network.
- Collaboration between engineers. Plan and prepare changes in a common way and use a logical inventory system to share engineering logic by means of templates etc. Especially when this is tied to a config/job generation engine, this becomes extremely powerful.
- Thinking things (better) through. As many engineering procedures have been done manually in the past, a lot of them are implicit. For example, many low-level network designs only focus on how to create new services. But you also need to take into consideration how you change and delete network services. These should be though off and tested as well before you start automating. The same goes for other processes that can be automated, such as testing after activation or triggering fault management systems to start monitoring when services are up.